Overview
Discover what makes Papra powerful
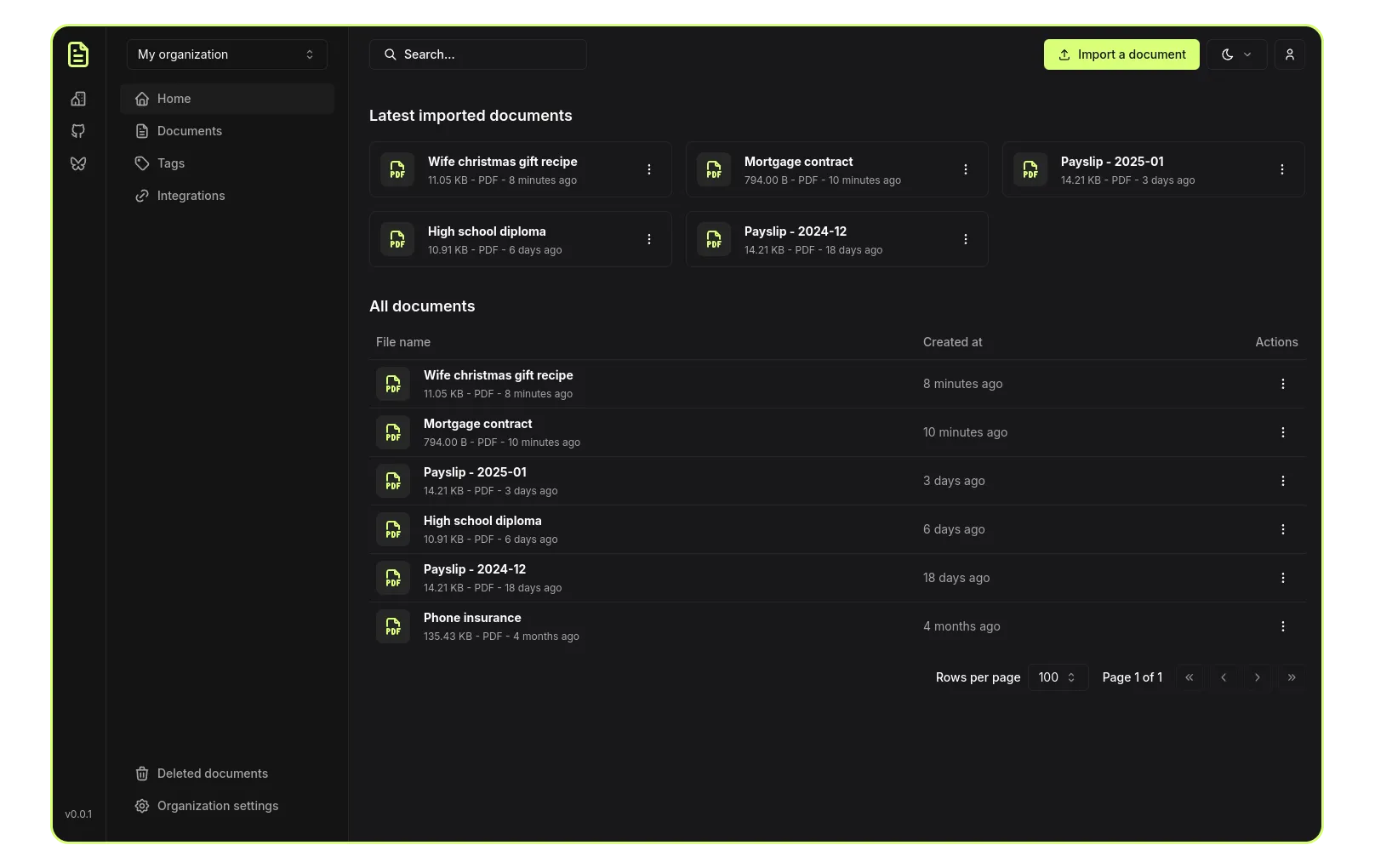
Papra is a lightweight, self‑hosted document management system engineered for developers who need an extensible, API‑centric archive. At its core it exposes a RESTful service that accepts file uploads, extracts text via OCR when necessary, and indexes the resulting content for full‑text search. The platform is built with a clear separation of concerns: a **Go** microservice layer handling business logic, an **Elasticsearch** backend for search, and a **PostgreSQL** relational store for metadata. This combination gives developers predictable performance while keeping the codebase approachable.
Backend
Search
Persistence
Storage
Overview
Papra is a lightweight, self‑hosted document management system engineered for developers who need an extensible, API‑centric archive. At its core it exposes a RESTful service that accepts file uploads, extracts text via OCR when necessary, and indexes the resulting content for full‑text search. The platform is built with a clear separation of concerns: a Go microservice layer handling business logic, an Elasticsearch backend for search, and a PostgreSQL relational store for metadata. This combination gives developers predictable performance while keeping the codebase approachable.
Architecture
- Backend – A statically compiled Go server (≈ 5 MB) that implements the Papra API, authentication via JWT, and a CLI for bulk operations. The server is container‑friendly, exposing health checks and Prometheus metrics.
- Search – Elasticsearch 8.x is used for vector‑based full‑text search and faceted filtering. The Go client communicates over the REST API, leveraging native analyzers for multilingual support.
- Persistence – PostgreSQL 15 stores user accounts, organization data, document metadata, and tagging rules. The schema is intentionally flat to simplify migrations; the Go
sqlxpackage handles query execution. - Storage – Files are persisted in an object store that can be swapped out via a simple interface. By default, the Docker deployment mounts a local directory (
/data/files) but supports S3-compatible backends with minimal configuration.
Core Capabilities
- API – CRUD operations for documents, tags, and organizations. Endpoints accept
multipart/form-datafor uploads and return JSON payloads with document IDs, extraction status, and search vectors. - Webhooks – Developers can register callbacks for events such as
document_uploadedortag_updated. The webhook payload is signed with HMAC to ensure authenticity. - SDK – A TypeScript SDK (available on npm) wraps the HTTP client, providing typed interfaces for all endpoints and automatic retry logic.
- CLI – The
papra-clitool allows scripted ingestion, bulk tagging, and export of metadata to CSV or JSON. It reads environment variables for authentication (PAPRA_API_KEY). - Tagging Rules – Rule definitions are stored as JSON in PostgreSQL and evaluated server‑side using a lightweight expression language (
go-expression). This lets developers enforce business logic without modifying the core code.
Deployment & Infrastructure
Papra ships as a single Docker Compose stack that pulls images from GitHub Container Registry. The stack comprises:
papra-api– the Go serviceelasticsearch– a single-node cluster (configurable to scale horizontally)postgres– the relational databaseminio– optional S3‑compatible storage (or bind mount to host)
The stack is production‑ready: each service exposes health endpoints, supports environment‑based configuration (via .env), and can be run behind a reverse proxy such as Traefik or Nginx. For high‑availability, developers can run a multi‑node Elasticsearch cluster and replicate the PostgreSQL database using Patroni or Patroni‑Postgres.
Integration & Extensibility
- Email Ingestion – Papra can generate a unique address per organization; forwarding an email to this address triggers automatic parsing of attachments and inline images.
- Folder Ingestion – A background worker watches a mounted directory (or an SFTP endpoint) and ingests any new files, applying tagging rules automatically.
- Custom Plugins – The API exposes a hook for “pre‑process” and “post‑process” stages. Developers can write small Go plugins that register with the service, enabling custom OCR engines or third‑party indexing services.
- Webhooks & Event Bus – Besides HTTP callbacks, Papra emits events to a Kafka topic (
papra-events) for downstream processing. This is ideal for integrating with CI/CD pipelines or analytics dashboards.
Developer Experience
The project emphasizes clear documentation: the official docs contain a dedicated Self‑hosting guide, an API reference with example payloads, and a Swagger UI for interactive testing. The codebase follows idiomatic Go conventions, making it straightforward to contribute or fork. Community support is active on Discord and GitHub Discussions, where feature requests are tracked in an open roadmap. Licensing under MIT ensures there are no commercial restrictions.
Use Cases
- Enterprise Archive – Companies can host Papra on-premises to comply with data residency regulations while still leveraging powerful search.
- DevOps Automation – CI pipelines can upload build artifacts, logs, or test reports to Papra via the CLI and then query them programmatically.
- Legal & Compliance – Law firms can ingest contracts, apply automatic tagging rules (e.g.,
client_id,contract_type), and retrieve documents via API for case management. - Personal Knowledge Base – Hobbyists can set up a local instance to store receipts, warranties, and PDFs, using the webhooks to sync with cloud services.
Advantages
Papra’s minimalistic design reduces attack surface and resource consumption, making it ideal for constrained environments (e.g., Raspberry Pi or small VPS). Its use of standard, open‑source components (Go, PostgreSQL, Elasticsearch) ensures high performance and portability. The API-first approach gives developers full control over integration patterns, while the built‑in ingestion mechanisms lower operational overhead. Compared to monolithic commercial DMS solutions, Papra offers comparable feature sets with zero licensing fees
Open SourceReady to get started?
Join the community and start self-hosting Papra today
Related Apps in other

Immich
Self‑hosted photo and video manager

Syncthing
Peer‑to‑peer file sync, no central server

Strapi
Open-source headless CMS for modern developers

reveal.js
Create stunning web‑based presentations with HTML, CSS and JavaScript

Stirling-PDF
Local web PDF editor with split, merge, convert and more

MinIO
Fast, S3-compatible object storage for AI and analytics
Weekly Views
Repository Health
Information

Explore More Apps

LibreKB
Open-source, self-hosted knowledge base in PHP and MySQL

OpenRemote
Free, open‑source IoT platform for device management and automation

Concrete CMS
Intuitive, secure content creation for editors and developers alike

ENiGMA½ BBS
Modern, nostalgic bulletin board for the 21st century

Directory Lister
Browse and share web folders with zero configuration

Stretto
Web‑based music player that syncs playlists and fetches lyrics