
About
A Docker‑compose template that quickly sets up a self‑hosted AI and low‑code environment, integrating n8n, Ollama, Open WebUI, Flowise, Qdrant and PostgreSQL for instant local AI workflow creation.
Capabilities
The Pydantic Lod Test MCP server is a specialized, self‑hosted AI starter kit that stitches together a powerful low‑code workflow engine with cutting‑edge local AI capabilities. It addresses the common pain point of developers needing a single, reproducible environment to prototype and deploy AI‑driven automation without relying on external cloud services. By bundling a Docker Compose stack that includes n8n, Ollama, Open WebUI, Flowise, Qdrant, and PostgreSQL, the server gives teams an instant, fully‑functional playground where data ingestion, model inference, vector search, and workflow orchestration coexist on the same network.
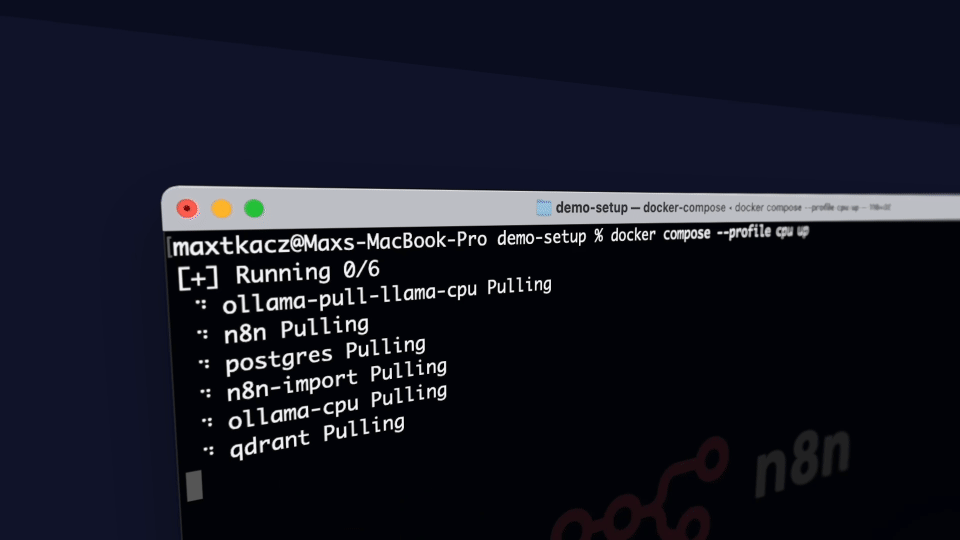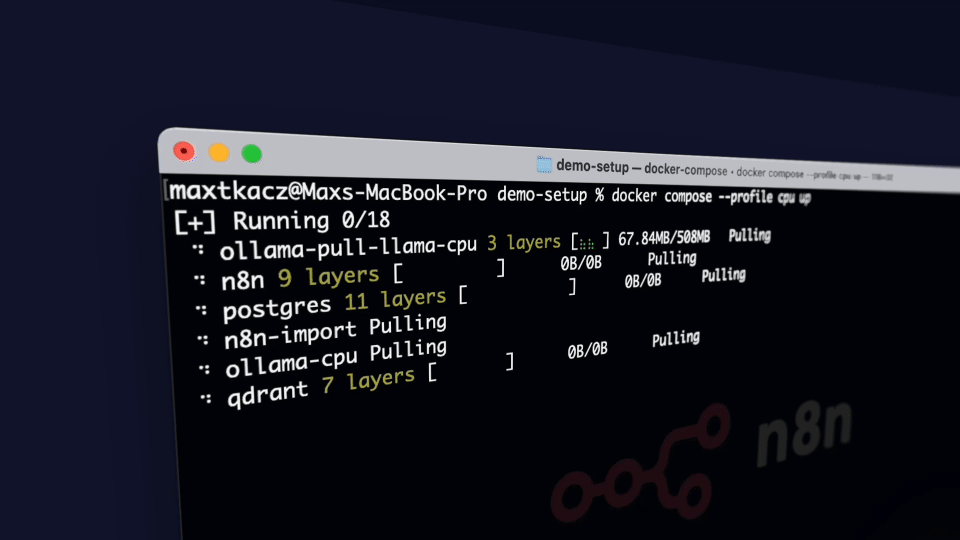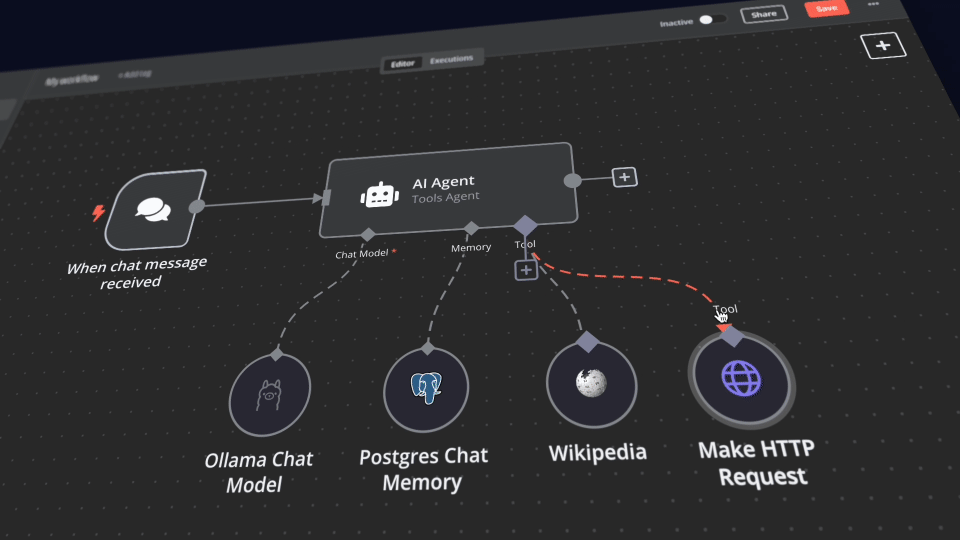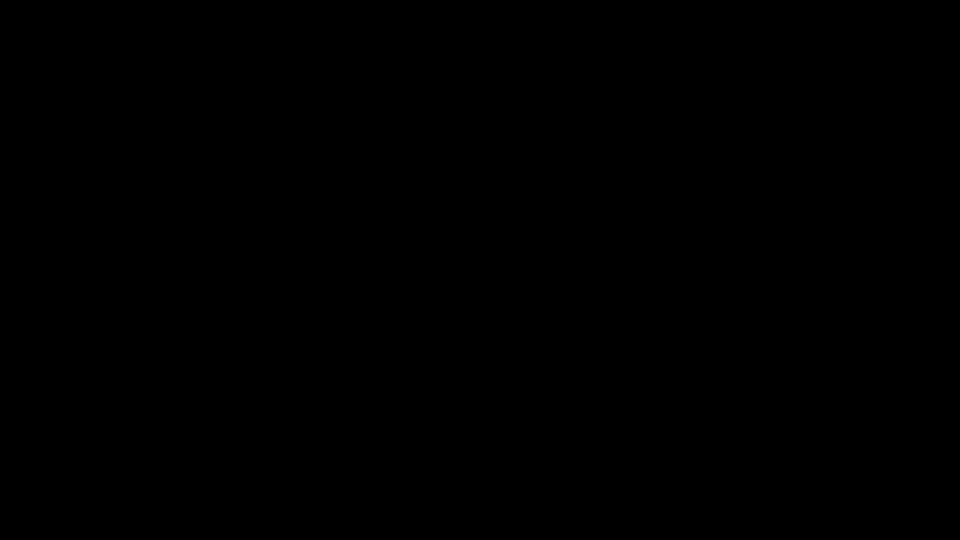
At its core, the server exposes a set of MCP resources that let an AI assistant (e.g., Claude) query and manipulate the underlying services. The n8n instance serves as the workflow orchestrator, providing a visual interface to chain together triggers, actions, and AI nodes. Ollama hosts local large language models, enabling private, low‑latency text generation. Open WebUI offers a familiar ChatGPT‑style chat layer that can talk directly to the local LLMs and even invoke n8n workflows as agents. Flowise complements n8n by offering a no‑/low‑code agent builder that can be exported into the n8n ecosystem. Qdrant supplies a fast, vector‑search backend for retrieval‑augmented generation (RAG), while PostgreSQL acts as the relational store for structured data and workflow metadata.
Developers benefit from several key features. First, full local privacy: all data and model inference stay on the host machine, eliminating external dependencies. Second, GPU acceleration is supported out of the box for Nvidia GPUs via Docker profiles, giving near‑real‑time inference on powerful hardware. Third, the stack is extensible; any n8n node or Flowise component can be wrapped as an MCP tool, allowing the AI assistant to trigger complex pipelines with simple prompts. Fourth, the integrated vector store (Qdrant) and database (PostgreSQL) mean that a single MCP client can manage both structured data and unstructured embeddings, simplifying stateful AI applications.
Typical use cases include building automated customer support agents that pull from a local knowledge base, generating content or code by invoking custom n8n workflows that fetch and transform data, or creating a personal AI assistant that can query local documents via RAG while orchestrating background tasks. In research settings, the server allows rapid prototyping of multimodal or chain‑of‑thought workflows without provisioning cloud resources. The MCP integration makes it trivial to embed these capabilities into larger AI ecosystems, letting assistants act as glue between human intent and a rich set of local tools.
Related Servers

MarkItDown MCP Server
Convert documents to Markdown for LLMs quickly and accurately

Context7 MCP
Real‑time, version‑specific code docs for LLMs
Playwright MCP
Browser automation via structured accessibility trees

BlenderMCP
Claude AI meets Blender for instant 3D creation

Pydantic AI
Build GenAI agents with Pydantic validation and observability

Chrome DevTools MCP
AI-powered Chrome automation and debugging
Weekly Views
Server Health
Information
Explore More Servers

Gaphor MCP Server
Model-driven diagram generation and validation for Gaphor

File Context Server
LLM-powered file system exploration and analysis

YouTube Watch Later MCP Server
Fetch your recent YouTube Watch Later videos quickly

Maven Dependencies MCP Server
Instant Maven version checks and updates

ServeMyAPI
Secure macOS Keychain API key storage for MCP clients

MCP Kafka Processor
Process events into Kafka topics with minimal setup